
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- Series
- 김성훈 교수님
- ML-Agent
- Laplacian
- 사이킷런
- paper
- reinforcement learning
- statistics
- Linear algebra
- optimization
- Jacobian Matrix
- David Silver
- unity
- Deep Learning
- 유니티
- 논문
- pandas
- list
- Python Programming
- 데이터 분석
- Hessian Matrix
- machine learning
- 딥러닝
- 리스트
- 강화학습
- neural network
- 판다스
- 모두를 위한 RL
- rl
- convex optimization
RL Researcher
강화학습(Reinforcement Learning) 개요 본문
1. 머신러닝과 강화학습
머신러닝은 크게 3가지로 분류가 됩니다.
-
지도학습(Supervised Learning)
-
비지도학습(Unsupervised Learning)
-
강화학습(Reinforcement Learning)
지도학습(Supervised Learning) : "정답"을 알고 있는 데이터를 이용해 컴퓨터(Machine)를 학습시킵니다. 컴퓨터(Machine)는 자신이 낸 답과 정답의 차이를 통해 지속해서 학습합니다.
Ex) 회귀분석(Regression), 분류(Classification)
비지도학습(Unsupervised Learning) : 지도학습과는 다르게 정답이 있는 것이 아닙니다. 데이터가 주어지면 비슷한 것끼리 묶어주는 식의 학습이 비지도 학습입니다. 비지도학습은 정답이 없이 주어진 데이터로만 학습합니다.
Ex) 군집화(Clustering)
강화학습(Reinforcement Learning) : "보상(Reward)"을 통해 학습합니다. 보상은 컴퓨터(Machine)가 선택한 행동(Action)에 대한 환경의 반응입니다. 이 보상은 직접적인 답은 아니지만 컴퓨터(Machine)에게는 간접적인 정답의 역할을 합니다. 보상을 얻게 하는 행동을 점점 많이 하도록 학습합니다.
2. Concept
-
에이전트(Agent) : 강화학습을 통해 스스로 학습하는 Machine, Agent는 환경에 대해 사전지식이 없는 상태에서 학습을 수행합니다. Agent는 자신이 놓인 환경에서 자신의 상태를 인식한 후 행동합니다. 그러면 Enviroment는 Agent에게 보상(Reward)를 주고 다음 상태를 알려줍니다. 이 보상(Reward)을 통해 Agent는 어떤 행동이 좋은 행동인지 간접적으로 알게 됩니다. 이러한 보상은 지속적으로 얻게 된다면 Agent는 좋은 행동을 학습할 수 있습니다.
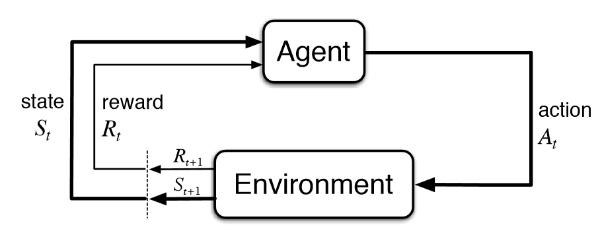
Agent는 자신의 행동과 행동의 결과를 보상을 통해 학습하면서 어떤 행동을 해야 좋은 결과를 얻게 되는지 알게 됩니다. 따라서 Agent는 점점 보상을 받는 행동을 자주 하게 되고 환경으로부터 더 많은 보상을 얻게 됩니다. 강화학습의 목적은 Agent가 Enviroment를 탐색하면서 얻는 보상들의 합을 최대화하는 "최적의 행동양식" 또는 "정책"을 학습하는 것입니다.
3. RL의 장점
강화학습의 장점은 환경에 대한 사전지식이 없어도 학습한다는 것입니다. 현실세계에서는 Agent가 어떠한 기능을 학습하려면 다양한 상황에 대한 정보가 있어야 합니다. 정보 없이 Agent는 시행착오를 통해 어떠한 기능을 학습합니다.
4. RL Problem
강화학습은 결정을 순차적(Sequential)으로 내려야 하는 문제에 적용됩니다. 나중에 포스팅하게 될 Dynamic Programming, Evolutionary Algorithm 등 문제를 푸는데 적용할 수 있습니다.
'Reinfrocement Learning' 카테고리의 다른 글
| 01. Introduction to Reinforcement Learning (0) | 2021.04.03 |
|---|---|
| 강화학습 공부 자료 (0) | 2021.02.27 |
| MAB Problem (0) | 2021.02.19 |
| Markov Decision Process(MDP) (0) | 2021.02.09 |
| 강화학습 문제와 가치기반 강화학습 문제의 풀이기법 (0) | 2021.02.08 |
