
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Python Programming
- Hessian Matrix
- Laplacian
- machine learning
- optimization
- 김성훈 교수님
- 딥러닝
- 모두를 위한 RL
- ML-Agent
- paper
- 리스트
- unity
- convex optimization
- pandas
- 판다스
- reinforcement learning
- David Silver
- statistics
- Deep Learning
- list
- rl
- 데이터 분석
- 강화학습
- 논문
- neural network
- Jacobian Matrix
- 사이킷런
- Series
- Linear algebra
- 유니티
RL Researcher
Lecture 3: Planning by Dynamic Programming 본문
Lecture 3: Planning by Dynamic Programming
Lass_os 2021. 2. 2. 12:53
- 동적 계획법은 큰 문제를 작은문제들로 나누고 작은 문제들의 해결책들을 찾은 후 모아 큰 문제를 푸는 것입니다.

- 동적 계획법의 두가지 조건에 대해서 보겠습니다.
- 큰 문제가 작은 문제들로 나뉠 수 있어야 합니다.
- Subproblem을 풀면 문제에 대한 정답을 저장해 두었다가 나중에 재사용합니다.
- MDP는 위 두 조건을 만족합니다.

- 동적 계획법은 MDP의 모든 지식을 알고 있습니다.
- 동적 계획법이 MDP의 계획에 사용됩니다.
- 쉽게 생각하면, Prediction은 value function을 찾는 문제이고, Control문제는 policy를 찾는 문제입니다.
- Prediction의 경우
- 입력: MDP $<S,A,P,R,\gamma>$ 그리고 정책 $\pi$
- 또는: MRP $<S,P^{\pi},R^{\pi},\gamma>$
- 출력 : 가치함수 $v_{\pi}$
- Control의 경우
- 입력: MDP $<S,A,P,R,\gamma>$
- 출력: 최적의 가치함수 $v_{*}$
- 그리고: 최적의 정책 $\pi_{*}$

- 동적 계획법은 다양한 분야에서 사용됩니다.

- 정책 $\pi$를 따라갔을 때 받을 Return 값이 Evaluation이기 때문에 이것은 Value Function을 찾는 문제라고 볼 수 있습니다.(Prediction문제)
- $v_{1} \rightarrow v_{2} \rightarrow ... \rightarrow v_{\pi}$
- 동기적 백업을 이용합니다.
- 각 반복은 $k + 1$
- 모든 스테이트 $s \in S$
- $v_{k+1}(s) 에서부터 v_{k}(s^{'})$까지 업데이트를 수행합니다.
- $s$는 다음 $s'$에 있다.

- Bellman Expectation Equation을 이용해서 제일 위의 값을 계속 업데이트 해 나갑니다.

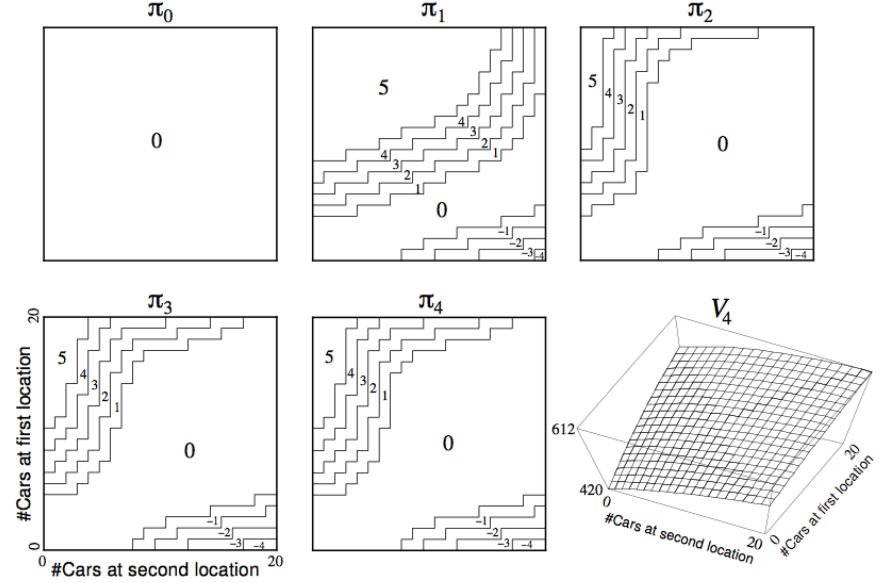
위의 예제는 정책 평가에 대한 예시입니다.



- 정책 $\pi$가 주어졌을 때
- Bellman Expection Equation을 이용한 수식을 통해 정책 $\pi$를 평가합니다.
$$v_{\pi}(s) = E[R_{t+1} + \gamma R_{t+2} + ... \mid S_{t} = s]$$
- greedy하게 행동해서 정책을 개선시킵니다.
$$\pi^{'} = greddy(v_{\pi})$$



- 결정론적 정책, $a = \pi(s)$
- 저희는 정책을 개선하기 위해서 greedy하게 행동할 수 있습니다.

- 제일 처음 수식으로 가게 된다면 향상은 멈추게 됩니다.
- 그 아래의 수식은 Bellman optimality equation은 그 아래의 식을 만족하게 됩니다.
- 결국 $\pi$는 최적의 정책값입니다.

- 정책 평가에서 꼭 $v_{\pi}$에 수렴해야 하는가?
- 아니면 조금더 일찍 끝내면 안되는가?
- Grid world예제의 $k=3$이라고 하면 3번 평가하고, 향상하면 안되는 것인가?
- 위의 글은 정책 반복에 대해 충족하게 되는 조건입니다.


- 최적은 두가지 요소로 나누어질 수 있습니다.
- 첫번째 행동 $A_{*}$은 최적이다.
- 다음 State $S^{'}$는 최적의 정책을 따라갑니다.

- 작은 문제들의 $v_{*}(s^{'})$을 알게 된다면은 한스텝의 lookahead를 통해서 $v_{*}(s)$ 구할 수 있습니다.
- Bellman optimality Equation을 통해 계산이 가능합니다.(max 때문에 역행렬을 계산할 수 없기 때문에 iteration하게 풀어야 합니다.)

- 다음의 그림은 최단 거리를 찾는 문제입니다.(Bellman Optimality Equation 사용)

- 문제 : 최적의 정책 $\pi$를 찾는 것
- 해결책 : 반복적으로 Bellman Optimality Backup을 적용하는 것입니다.
- 정책 반복과는 다르게 가치 반복은 정책이 없습니다.
- 동기적 백업을 사용합니다.
- 각 반복은 $k + 1$
- 모든 스테이트 $s \in S$
- $v_{k+1}(s) 에서부터 v_{k}(s^{'})$까지 업데이트를 수행합니다.
- $s$는 다음 $s'$에 있다.
- 정책 반복과 달리, 가치 반복에는 명시적인 정책이 존재하지 않습니다.

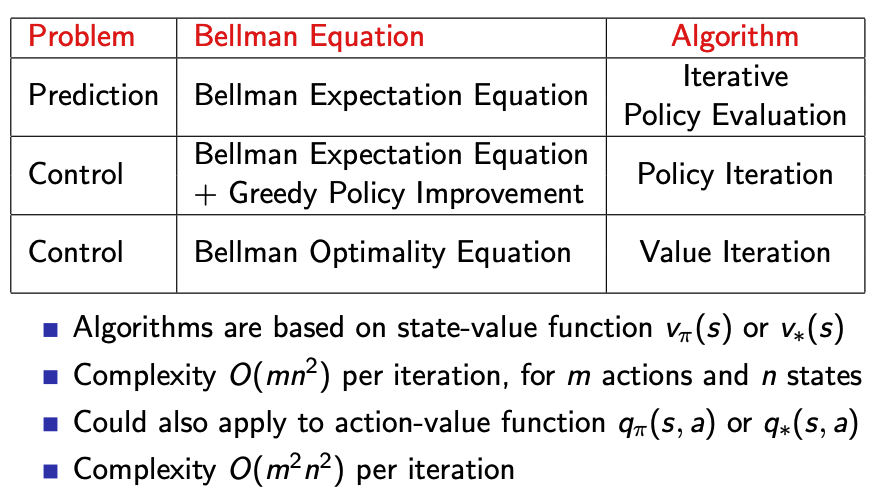
- 동기적 동적 계획 알고리즘은 상태가치 함수 $v_{\pi}(s)$ 또는 $v_{*}(s)$를 기반으로 합니다.
- n개의 State, m개의 행동에 대한 반복당 복잡성은 $O(mn^{2})$입니다.
- $q_{\pi}(s,a)$ 또는 $q_{*}(s,a)$에도 행동 가치함수를 적용할 수 있습니다.
- 반복당 복잡성은 $O(mn^{2})$입니다.

- DP 방법론은 모두 동기적 백업을 이용합니다.
- 모든 State들이 parallel하게 백업이 됩니다.
- Agent가 선택한 각 상태에 대해 적절한 백업을 적용합니다.
- 동기적 백업을 사용할 경우에 계산을 크게 줄일 수 있습니다.
- 모든 상태가 계속해서 선택되게 되는 경우에는 값이 수렴하게 됩니다.

- 위는 비동기적 동적 계획에 대한 세가지 간단한 아이디어에 대해 설명하고 있습니다.


- Bellman 오류의 크기를 이용하여 State에 대한 선택을 안내해 줍니다.

- 위의 3가지 그림은 동기적 DP의 예시에 대해서 설명하고 있습니다.

- DP는 Full-Width Backup을 사용합니다.
- 중간 크기의 문제에 대해서만 적용이 가능합니다.(커지면 기하급수적으로 증가)









'Reinfrocement Learning > David-Silver Lecture' 카테고리의 다른 글
| Lecture 6: Value Function Approximation (0) | 2021.02.04 |
|---|---|
| Lecture 5: Model-Free Control (0) | 2021.02.03 |
| Lecture 4: Model-Free Prediction (0) | 2021.02.03 |
| Lecture 02 : Markov Decision Processes (0) | 2021.02.02 |
| Lecture 1: Introduction to Reinforcement Learning (0) | 2021.02.01 |



