
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 유니티
- 딥러닝
- 데이터 분석
- 사이킷런
- Linear algebra
- Hessian Matrix
- rl
- 리스트
- unity
- 모두를 위한 RL
- Jacobian Matrix
- 판다스
- ML-Agent
- Laplacian
- convex optimization
- neural network
- Deep Learning
- 강화학습
- Series
- Python Programming
- optimization
- reinforcement learning
- list
- 논문
- David Silver
- statistics
- machine learning
- 김성훈 교수님
- paper
- pandas
RL Researcher
Lecture 5: Windy Frozen Lake Nondeterministic world! 본문
Lecture 5: Windy Frozen Lake Nondeterministic world!
Lass_os 2021. 2. 10. 01:09
실제 Frozen Lake문제는 바람이 부는 Frozen Lake문제입니다. Agent가 $s$에서 시작한다고 했을 때, 강의 환경을 알지 못합니다. 잘하면 $s_{1}$이라는 State에 도착을 하겠지만, 바람도 심하게 불고 미끄럽기 때문에 아래쪽이나 2칸을 더 가게되는 상황이 발생할 수 있습니다. 그래서 오른쪽으로 갈려고 해도 항상 오른쪽으로 가지는 것이 아닙니다.

우리는 위에서 설명한 이것을 nondeterministic 즉 Stochastic이라고 부릅니다. 오른쪽으로 간다고 했을 때 오른쪽으로 갈수 없을 수도 있으며 다른 위치에 도착해 있을 수도 있기 때문에 보상도 다를 수 있습니다. 우리가 이전까지 했던 바람이 불지않는 Frozen Lake는 Deterministic Game이라고 부릅니다. 항상 정해져 있습니다. 오른쪽으로 간다고 했을 때 오른쪽으로 가지게 되며, 이동에 대해 같은 보상을 받게 됩니다.
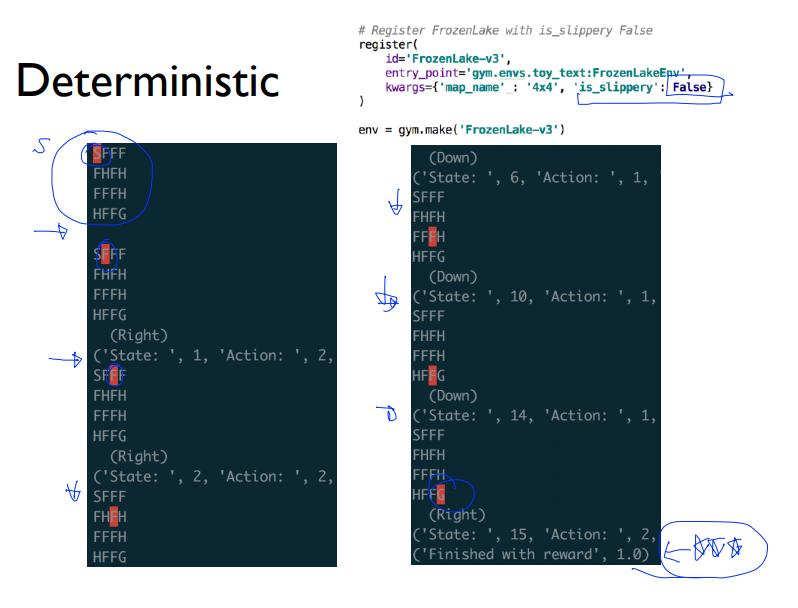
Deterministic한 Game이 어떻게 진행될까요? 위의 코드 중 is_slippery : False를 주었습니다 이 조건은 Frozen Lake게임을 하는데 미끄럽지 않게 설정을 하는 것입니다.

이번엔 Stochastic한 Game에 대해서 알아보겠습니다. 'FrozenLake-v0'을 사용하면 is_slippery가 자동으로 참이 되기 때문에 이렇게 사용하면 됩니다. 시작은 같지만 오른쪽으로 움직이는 키를 눌렀을 때 오른쪽으로 움직이지 않았습니다. 이말은 즉 미끄러졌다는 말입니다. 한번더 오른쪽으로 눌렀지만 불행히도 미끄러져서 움직이지 않았습니다. 결과적으로 첫 번째 episode는 H에 빠지게 되면서 게임이 종료가 됩니다.

하지만 저희는 앞서 배웠던 Q Function을 이용할 수 있습니다. Q-Function을 통해 학습을 시킬 수 있을까요?
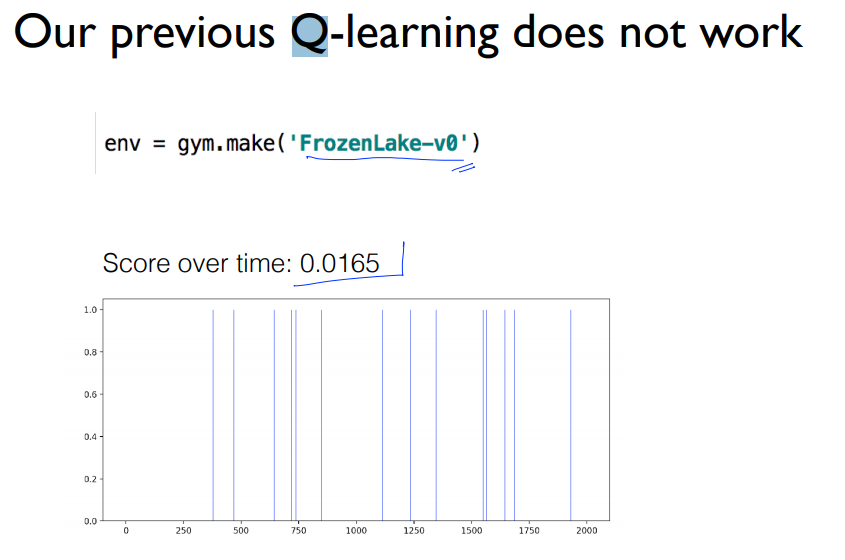
하지만 위의 Q Function을 사용했을 때 결과는 예상치 못하게 0.0165의 성공률을 보입니다.

왜 그럴까요? 결과적으로 $s$라는 상태에 도착을 했다고 가정합시다. 오른쪽으로 가면 괜찮다고 Q Function을 보면 알 수 있습니다. 하지만 Q Function은 거짓말 하지않았습니다. 하지만 미끄러질 수 있다는 가정이 있기 때문에 다른 위치에 도달할 수도 있기 때문입니다.

해결책으로 저희는 Q Function을 이용할 것입니다. 하지만 Q Function을 다 이용하지 않고 조금만 이용할 것입니다.
이 것은 실행활에서처럼 한 멘토만 따르는 것이 좋은 것이 절대 아닙니다.

위에서 설명한 한명의 멘토가 아닌 여러명의 멘토가 있으면 좋다라는 것의 예시입니다.

$s_{5}$에 위치한다고 가정합시다. 그렇다면 $s_{6}$의 Q함수를 통해서 $s_{5}$값을 업데이트 하게 될 것입니다. 하지만 모들 Q 함수의 값의 말을 100%따르지 않고 10%정도만 참고하여 따릅니다.

제일 위의 식은 이전에 Q를 업데이트 시켜왔던 방식입니다. 저 식을 10%만 받아들인다는 것입니다. 이것이 바로 Learning rate입니다.


이 $\alpha$값은 Hyperparameter값이라 사용자가 변경이 가능합니다.

우리는 이 알고리즘을 nondeterministic환경 즉 Stochastic한 환경에서도 사용이 가능합니다.
- $\hat{Q}$값을 0으로 initialize합니다.
- 현재 State를 관찰합니다.
- 무한반복을 수행합니다. :
- Action $a$를 취합니다.(Expoitation & Exploration방법을 이용)
- 보상과 다음 State를 받아옵니다.
- Q를 업데이트 합니다.($\alpha$(Learning rate 사용))

우리가 예측하는 Q값이랑 실제 Q값이 수렴을 하게 될까요??
- 많이 반복(infinity iteration)을 하게 되면 $\hat{Q}$값은 $Q$값에 수렴하게 됩니다.
'Reinfrocement Learning > 모두를 위한 RL' 카테고리의 다른 글
| Lecture 7: DQN (0) | 2021.02.10 |
|---|---|
| Lecture 6: Q-Network (0) | 2021.02.10 |
| Lecture 4: Q-Learning (table) (0) | 2021.02.09 |
| Lecture 3: Dummy Q-learning (table) (0) | 2021.02.09 |
| Lecture 2: Playing OpenAI GYM Games (0) | 2021.02.09 |



