
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 강화학습
- David Silver
- convex optimization
- 판다스
- unity
- 사이킷런
- list
- 김성훈 교수님
- Python Programming
- Laplacian
- paper
- Jacobian Matrix
- optimization
- pandas
- 데이터 분석
- Series
- 논문
- 모두를 위한 RL
- rl
- machine learning
- 리스트
- neural network
- 딥러닝
- Hessian Matrix
- Deep Learning
- Linear algebra
- ML-Agent
- statistics
- 유니티
- reinforcement learning
RL Researcher
Lecture 7: DQN 본문
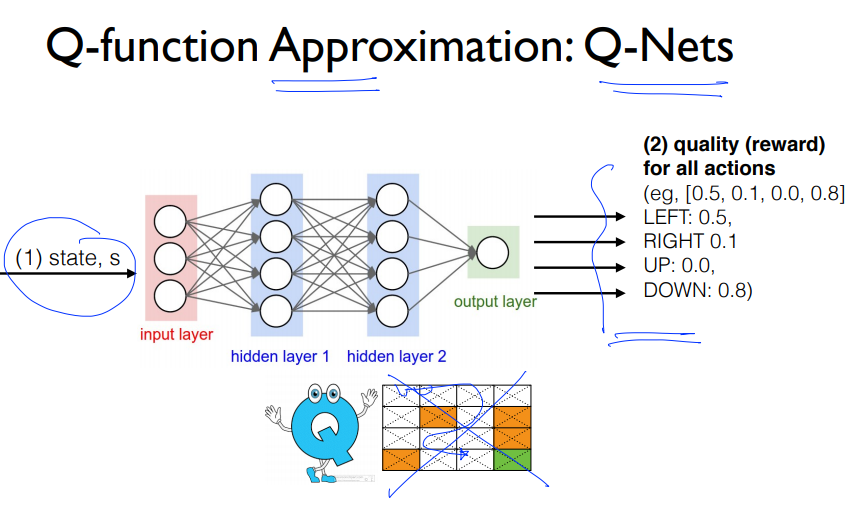
Q 함수의 근사가 Q-Net입니다.

Q-Nets 자체도 쉬운 문제에 대해서 불안정한 상태를 보였습니다.

여러 문제들 때문에 $\hat{Q}$는 Q에 수렴하지 못했습니다.


위의 Q-Net의 문제를 해결한 알고리즘이 DQN알고리즘입니다.

두가지 큰 문제가 무엇인지 봅시다.
- 샘플 데이터간의 상관계수가 있다
- 타겟이 흔들린다.

Q-Net을 초기화 시킨 후, initalize하고, Q-Net을 통해서 어떠한 Action을 할지 정합니다. 그런 다음 루프를 돌면서 Action을 취하면서 이동한 State에 대해서 환경과 보상을 받아옵니다.

CartPole예제를 들면 5개의 Episode들이 받아오는 값들이 상관적일 것입니다.

두번째 문제는 타겟이 움직인다는 문제인데. 예측값과 Y Label(target)간의 오차를 통해서 계산하는 수식입니다.

위의 식을 정리하면 다음과 같습니다. 결국에는 학습에 필요한 weight를 같이 사용합니다. 학습을 하면서 weight값이 움직일텐데, 예측값이 기존의 Y값과 비슷해 지는데, 현재의 정답인 Y값은 weight에 따라 같이 움직이기 때문에 멀어지게 되는 현상이 발생합니다.

위와 같은 해결책을 통해서 2가지 문제를 해결하였습니다.
- Go deep
- Capture and replay
- Separate networks : create a target network
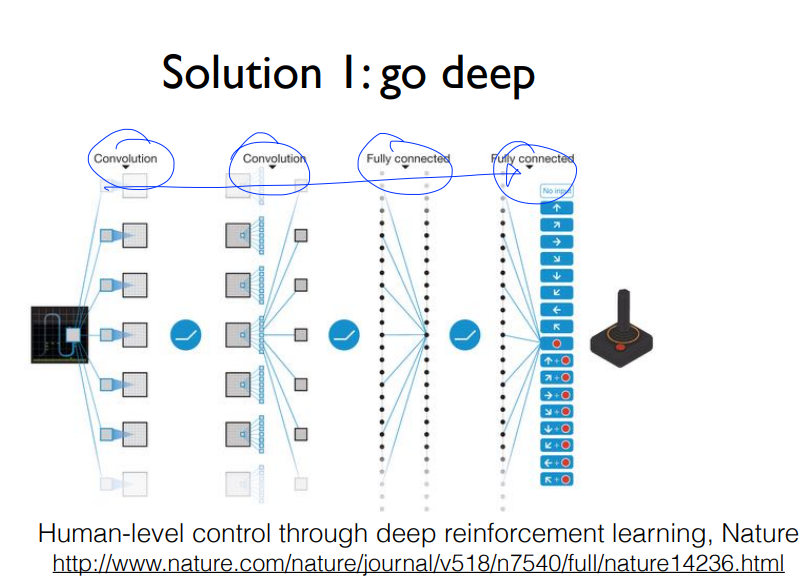
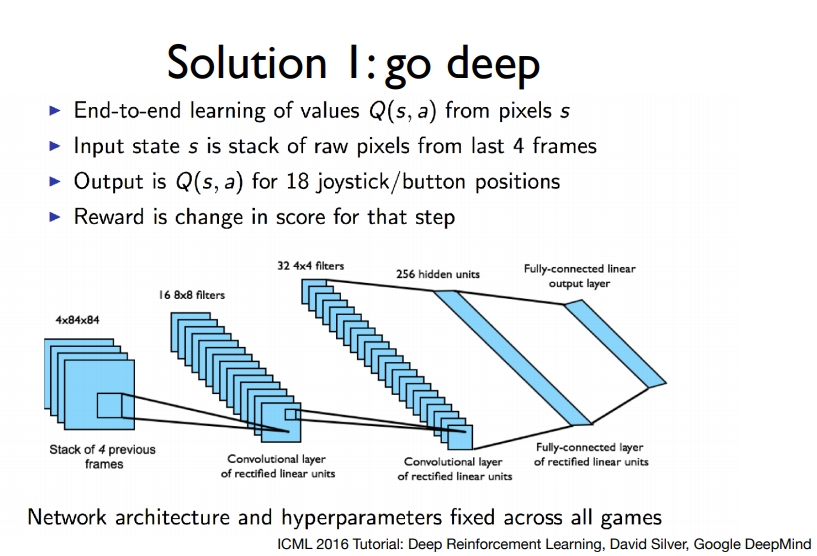
깊게 간다는 것은 깊은 신경망을 통해서 학습한다는 것입니다.
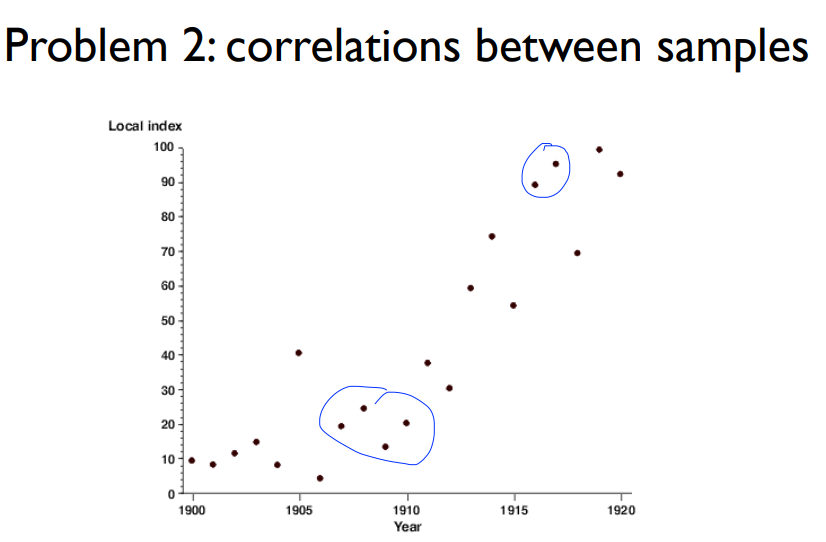
각자간의 correlation을 가지고 있는 것으로 학습을 시키면 전체에 대한 학습이 불가능할 것입니다.
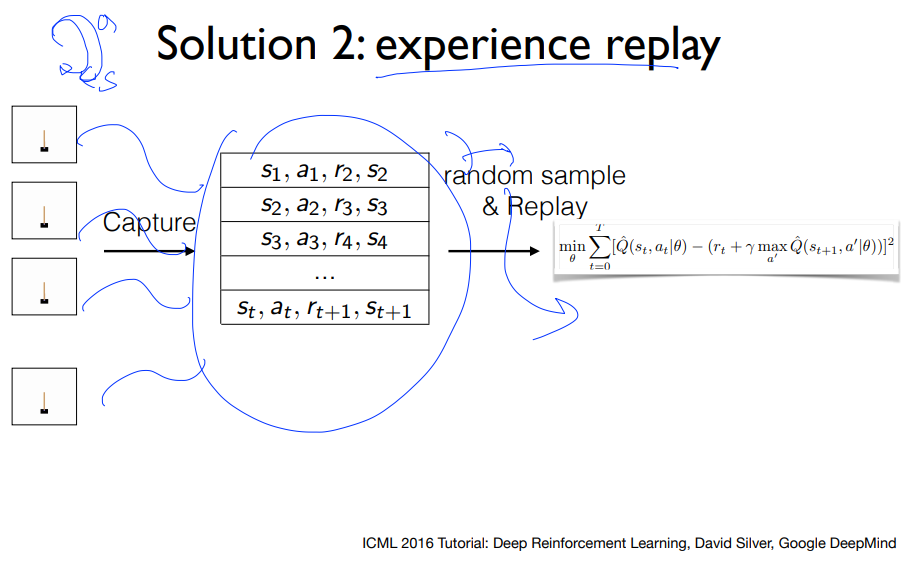
위의 문제점의 해결책은 다음과 같습니다.
- 버퍼를 통해서 저장합니다.
- 일정 시간이 지나고 나서 버퍼에서 랜덤하게 가져와서 학습시킵니다.

한번 Action을 취한 다음 학습시키지 않고, D라는 버퍼에 저장한 후에 학습을 시킬때 D라는 버퍼에서 랜덤하게 샘플링하여 미니배치로 만들어 학습시킵니다.
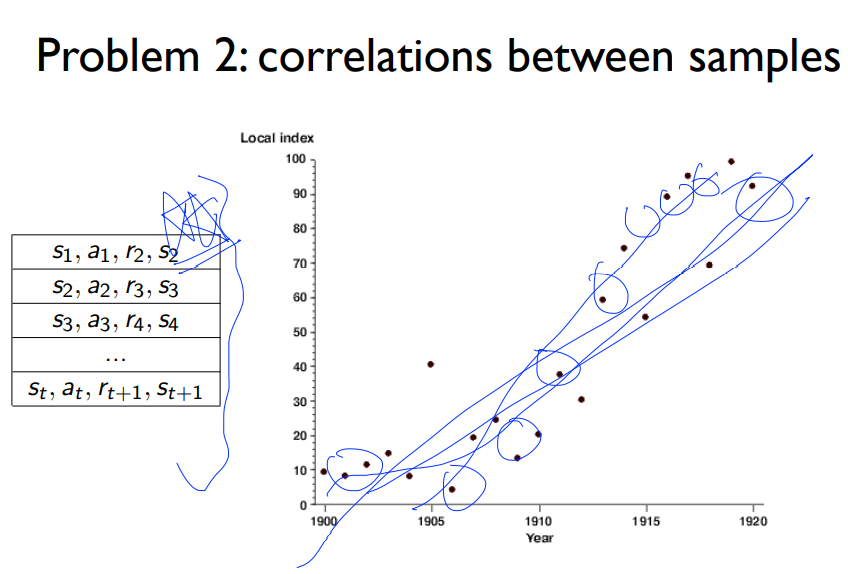
전체 스페이스를 모르기 때문에 전체에 대한것은 학습시키지 못하지만 그중 랜덤한 샘플들을 뽑아서 선을 긋는다면 전체 데이터에 대한 선과 굉장히 유사해 집니다.

타겟이 움직이는 문제에 대해서는 위에서도 설명했듯이 같은 weight를 공유하는 상태에서 예측치가 초기의 정답과 가까워지지만 현재의 정답은 weight에 의해서 점점 멀어지는 현상을 말합니다.

이 문제점의 해결책은 Network를 한개 더 만드는 것입니다. 위의 수식을 보면 서로 다른 weight를 사용하고 있습니다.업데이트를 예측값의 weight값만 업데이트를 수행합니다.
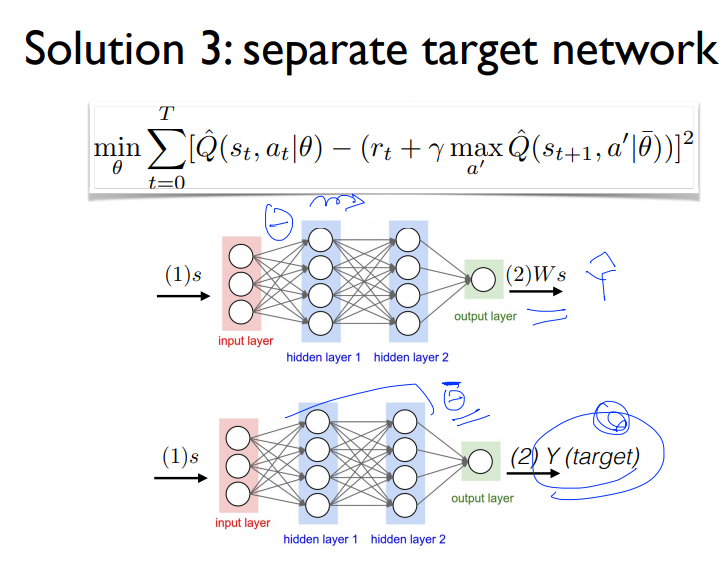
다른 weight 를 사용하고 target값의 weight는 업데이트하지 않고 예측치의 Network값만 업데이트를 수행합니다.
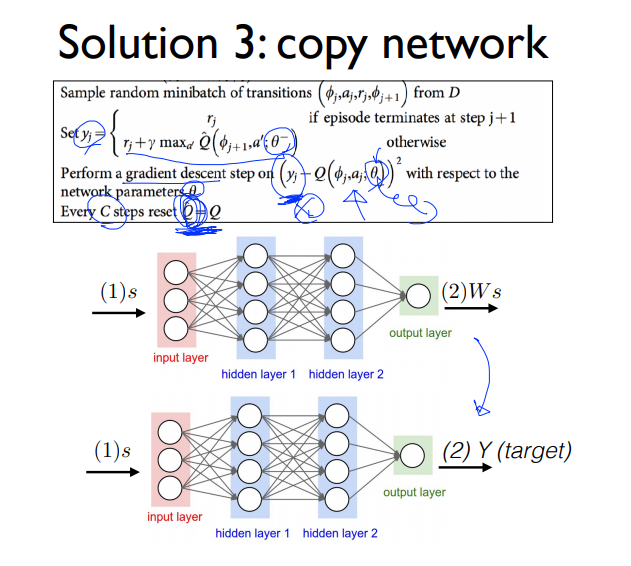
물론 끝까지 target값을 업데이트를 안하는 것은 아닙니다. 어느정도 시간이 지난 후에 복사를 수행합니다.

'Reinfrocement Learning > 모두를 위한 RL' 카테고리의 다른 글
| Lecture 6: Q-Network (0) | 2021.02.10 |
|---|---|
| Lecture 5: Windy Frozen Lake Nondeterministic world! (0) | 2021.02.10 |
| Lecture 4: Q-Learning (table) (0) | 2021.02.09 |
| Lecture 3: Dummy Q-learning (table) (0) | 2021.02.09 |
| Lecture 2: Playing OpenAI GYM Games (0) | 2021.02.09 |



